Bahareh Nobar

Machine learning engineer, Data scientist, NLP engineer, Generative AI
Data Scientist
Technical Skills
- Programming languages: Java, Python
- Libraries and Frameworks: Keras, NL Toolkit, Numpy, Pandas, PySpark, PyTorch, Scikit-learn, SciPy, Seaborn, TensorFlow
- Machine learning: A/B Testing, Algorithms, Anomaly Detection, Artificial intelligence, BERT, Big Data, BPE tokenizer, Computational Linguistics, Conversational AI, Data Engineering, - Data Mining, Data Modeling, Debugging, Deep Learning Methods, End-point Deployment, Ensemble Methods, Generative AI, Generative model, Hypotheses testing, K-means clustering, langchain , Language Model , Linear regression, Llama2, Logistic regression, Neural Networks, Quantization, Speech Recognition, Statistics, Supervised, Support Vector Machine (SVM), Tagging, Text Classification, Text-to-Speech, Time series signal, Tokenization, Transformer models, Unsupervised, Wav2vec, word2vec, Word Embeddings
- Cloud: API, AWS EC2, AWS EMR, AWS S3, AWS Sagemaker,GCP, VertexAI, Gradio
- Databases: MongoDB, MySQL, NoSQL, SQLite, PostgreSQL
Education
-
M.S., Data Science The University of New Haven, May 2024 -
B.S., Computer Science The University of Kharazmi, September 2016
Work Experience
Machine Learning Engineer @ FluteSpace (December 2024 - Present)
- Automated high-quality dataset curation for medical speech-to-text using YouTube + Google Speech API, correcting errors with ChatGPT and prompt engineering, resulting in a clean 23-hour dataset.
- Simulated radiology scenarios with LLM to collect 40 speaker references, using XTTS (latest Coqui TTS model) to generate 13 hours of diverse, accent-rich data by synthesizing audio with less than 10 seconds of speaker reference during inference.
- Verified dataset quality using Word Error Rate (WER) analysis with Deepgram, fine-tuning Whisper large turbo and Whisper large v3 models, reducing WER by 23%.
- Developed a Retrieval-Augmented Generation (RAG) system integrated with LLM and XTTS to create an advanced speech chatbot assistant.
Graduate Research Assistant @ University of New Haven (October 2022 - May 2024)
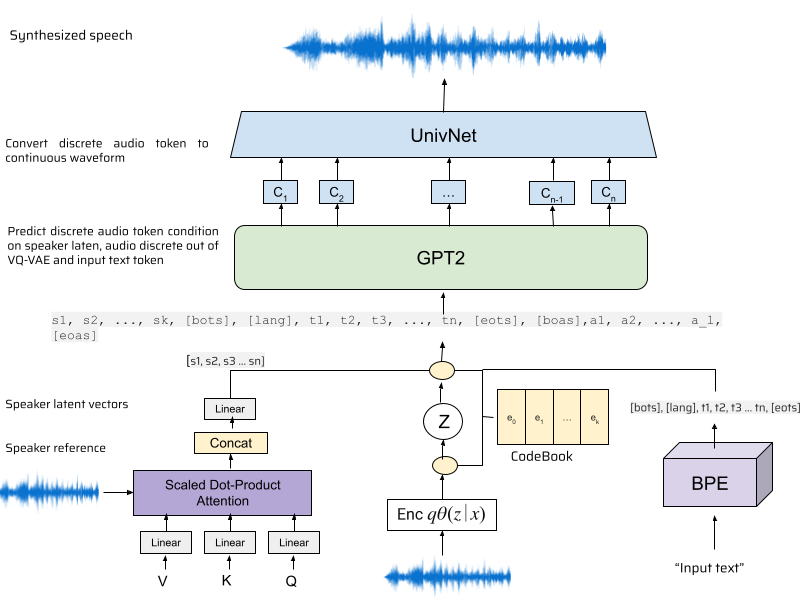
- Integrated and deployed a Large Language Model (LLM) based on state-of-the-art TTS for low resource languages, achieving an exceptional Mean Opinion Score (MOS) of 4.2 out of 5 across multiple low resource languages.
- Automated key performance metrics of the low-resource TTS evaluation system based on 5 ontologies, resulting in 40% faster evaluation times and 25% accuracy improvement by fine-tuning the wav2vec model for low-resource languages.
- Enhanced AI/ML platform infrastructure and performance management by optimizing a large language model (LLM)-based text-to-speech system. Leveraged multi-GPU setups and advanced GPT training techniques, achieving a 20% faster convergence rate for the model
- Automated the creation of a high-quality Text-to-Speech (TTS) dataset for a low-resource language using the latest open-source data quality tools, improving accessibility and speech synthesis by 12%. This process enhanced user experience and broadened product reach.
Data Analyst @ Maadiran Industries Group, TCL Exclusive Home Appliance representative (December 2017 - January 2022)
-
Developed and managed budgets to optimize business metrics, automated workflows, and monitored Key Performance Indicators (KPIs), resulting in a 25% increase in on-time delivery and $80,000 reduction in quarterly shipping costs.
- Improved technical and non-technical key stakeholders’ decision-making efficiency by 20% through statistical methods, Python, analytics software, and data visualization tools, resulting in enhanced business strategy, provided technical solutions for business problems, and meaningful insights.
- Enhanced query performance through strategic optimization techniques, including setting efficient indexes, separating log files from data files, and implementing various other optimization methods.
- Effectively trained customers in financial systems, resulting in a significant increase in employees’ knowledge and a 20% improvement in software usage efficiency.
Projects
Multilingual Speech Chatbot
Evers Inc. (09/2024 - 11/2024)
- Developed models for a scalable, real-time, multi-modal end-to-end data pipeline that handles multilingual speech prompts, utilizing OpenAI’s embedding technology for creating a Vector DB and the Whisper model for speech-to-text conversion, enhancing data security and improving information retrieval.
- Implemented predictive modeling and deployed a multi-language pipeline with Gradio and RAG, creating a profitable and cost-effective chatbot that supports new features, drives competitive advantage, and enables profitable growth through improved user engagement.
- Optimized each component of the chatbot for speed in real-time applications using techniques like semaphore, threadpool manager, and batching.
NLP Multilingual Teacher Assistant Chatbot
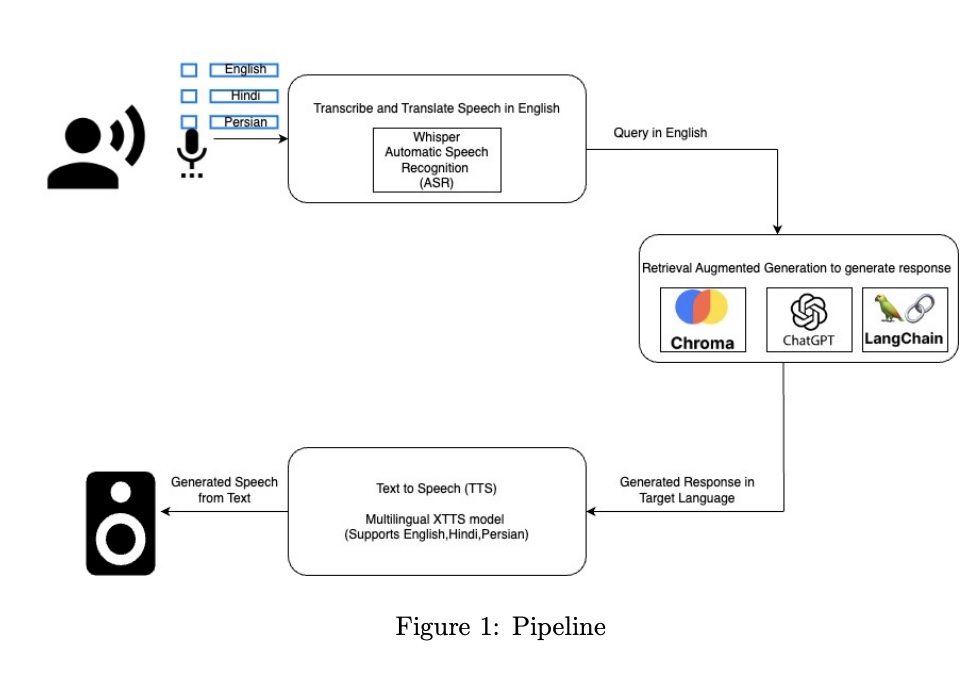
- Developed a scalable, real-time, API Gateway-integrated, multi-modal end-to-end data pipeline that handles speech prompts in Persian, English, and Hindi. Utilized OpenAI’s embedding technology for creating Vector DB and the Whisper model for converting speech to text, enhancing data security and improving information retrieval.
- Implemented and deployed the entire pipeline to operate seamlessly across multiple languages and integrates robustly with Gradio, providing a scalable, cost-effective chatbot service that supports new features development and significantly drives growth.
Explore the Deployment video on Lambda GPU
AI-Driven Supply Chain Optimization for Pharmaceuticals
-
Optimizing Delivery Schedules: Utilized Dense Neural Networks (DNN) for predicting deviations between scheduled and actual delivery times, achieving a test RMSE of 22.84 compared to the benchmark RMSE of 29.22. Extensive feature engineering was performed on delivery times and schedules, with results visualized and presented on a Power BI dashboard for non-technical stakeholders.
-
Forecasting Monthly Freight Costs: Employed LSTM and ARIMA models to forecast monthly freight costs, with the LSTM model achieving a test RMSE of 529,783.70, significantly better than the naive benchmark RMSE of 861,773.48. Feature engineering and extraction from both structured and unstructured data were conducted, with findings visualized in Power BI.
Summary of Findings
| Model | Objective | Target Variable | Model Architecture | Performance Metric | Training RMSE | Test RMSE | Benchmark RMSE |
|---|---|---|---|---|---|---|---|
| DNN | Optimize delivery schedules | Schedule v Actual | Dense Neural Network (4 layers) | RMSE | 20.86 | 22.84 | 29.22 |
| LSTM | Forecast monthly freight costs | Freight Cost (USD) | LSTM Network (1 LSTM layer) | RMSE | 292287.38 | 529783.7 | 861773.48 |
| ARIMA | Forecast monthly freight costs | Freight Cost (USD) | ARIMA (2,1,2) | RMSE | 323737.57 | 565322.23 | 861773.48 |
Stock Action Recommendation with Fine-Tuned Transformer-Based Models
-
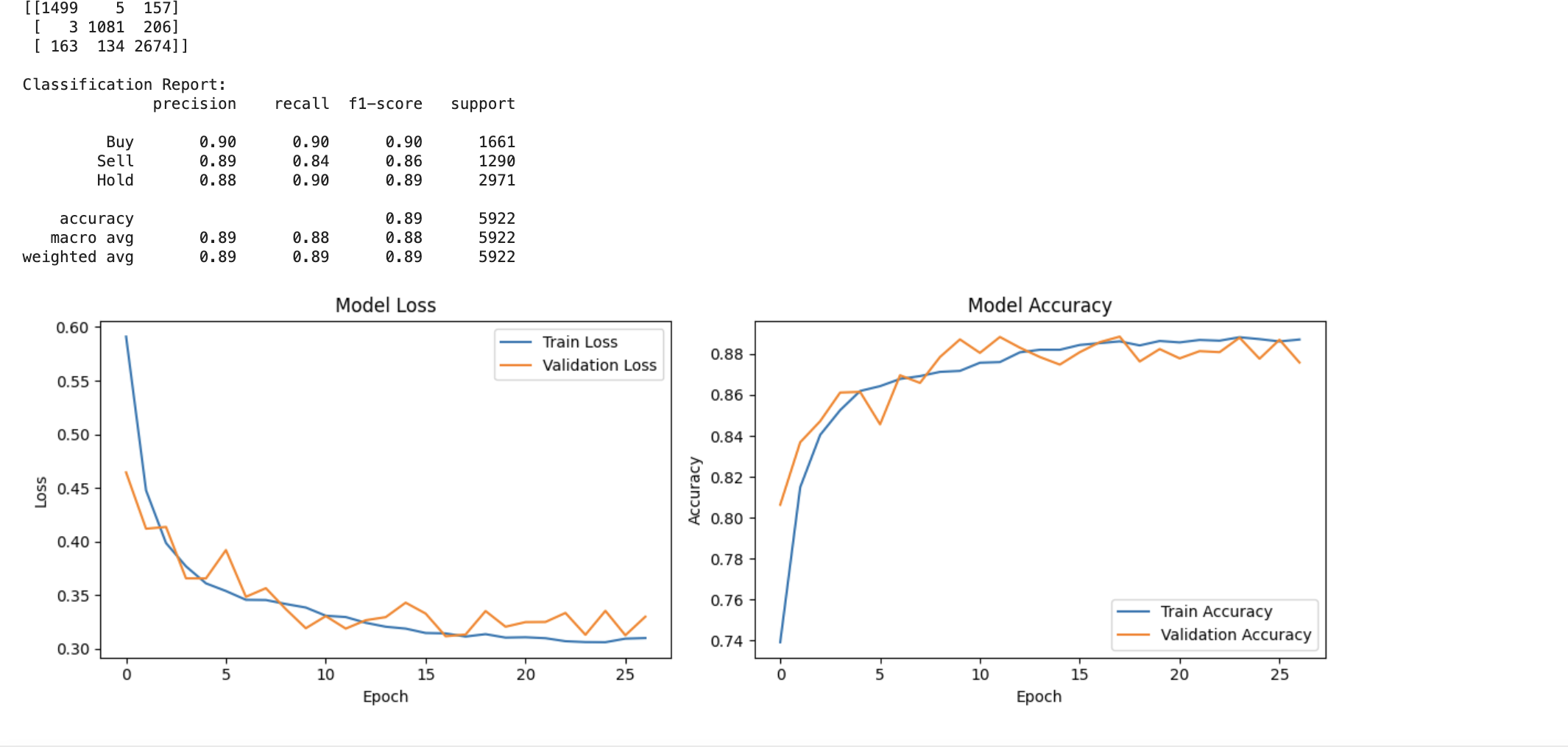
Objective: Developed a transformer-based model to predict stock market actions (Buy, Sell, Hold) using historical price data and technical indicators, achieving a test accuracy of 0.89.
-
Data Preprocessing: Sourced data from Databento and engineered features like RSI, MACD, OBV, and Bollinger Bands. Data was normalized, cleaned, and organized into sequences for model input.
- Signal Logic: The Buy, Sell, and Hold signals were determined based on the Relative Strength Index (RSI) indicator:
- Buy Signal: Assigned when RSI < 30.
- Sell Signal: Assigned when RSI > 70.
- Hold Signal: Assigned when 30 ≤ RSI ≤ 70. These signals are generated by creating sequences of historical data and labeling them according to the RSI values at the end of each sequence, allowing the model to learn from the underlying price movement patterns.
-
Model Architecture: Implemented a transformer model with 12 layers, incorporating multi-head attention, feed-forward networks, and dropout for regularization. The model included 5,912,533 trainable parameters, optimized for complex pattern recognition in time series data.
-
Training: Utilized techniques such as early stopping and a custom learning rate scheduler to optimize training. Mixed precision was enabled for faster computation without sacrificing accuracy.
- Results: The model demonstrated robust performance across all action classes:
- Buy Signal: Precision: 0.90, Recall: 0.90, F1-score: 0.90
- Sell Signal: Precision: 0.89, Recall: 0.84, F1-score: 0.86
- Hold Signal: Precision: 0.88, Recall: 0.90, F1-score: 0.89
- Conclusion: The fine-tuned transformer model effectively predicts stock market actions, highlighting the potential of advanced deep learning techniques in financial analysis.
 For more details, visit the full repository: Stock Recommendation with Transformer
For more details, visit the full repository: Stock Recommendation with Transformer
Anomaly Detection in Time Series Medical devices Signal
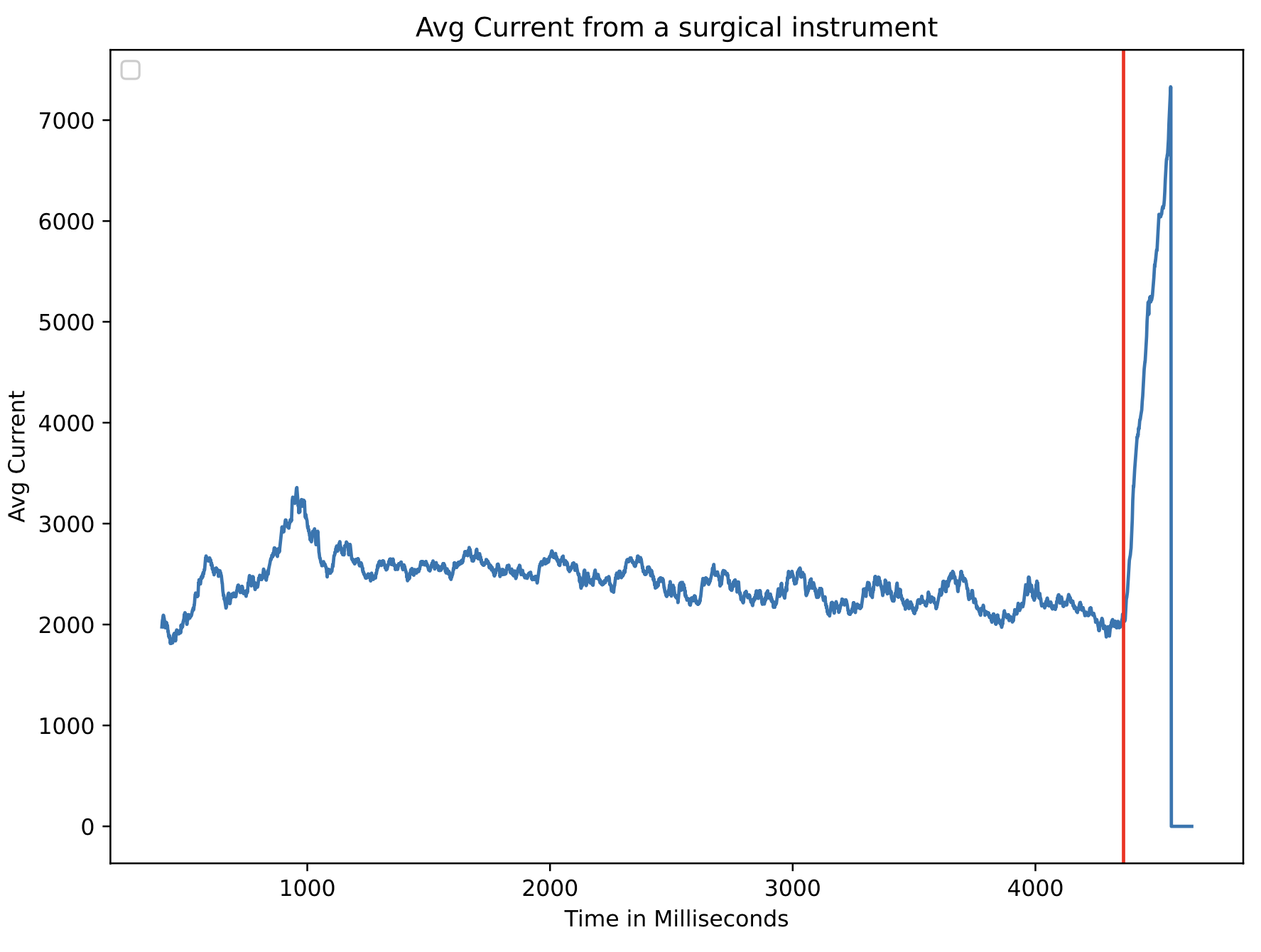
- Enhanced medical device (surgical staplers) failure prediction by 25% and decreased operational downtime by 20% by integrating machine learning algorithms. These improvements led to more accurate equipment failure predictions and reduced operational interruptions.
- Determined the most effective generative model for fault detection by assessing Variational Autoencoder (97%), Generative Adversarial Network (95%), and Hidden Markov Model (82%), resulting in enhanced fault detection in 6 months.
Automated Chest X-Ray Analysis for Pneumonia Detection
- Enhanced image processing algorithm by fine-tuning ResNet-50, CNN, and transformer-based models to extract nanometer-level information, improving precision by 20%.
- Developed a user-friendly web interface for real-time medical image analysis using computer vision techniques, facilitating rapid assessment and treatment planning.
Explore the Hugging Face Space
Malware classification of PE Files by help of Feature Extraction and Deep learning models
- Vectorize PE Files: Convert PE files into numerical vectors by extracting and counting the frequency of n-grams (byte sequences), then combine these n-gram frequency features with additional features derived from the PE file’s metadata (DLL imports and section names), and vectorize the text data using HashingVectorizer and TfidfTransformer.
- Deployed a PE file classification model on AWS SageMaker for easy client access, incorporating DevOps practices for simplified interaction with the model and ensuring a seamless user experience.
-
Developed and deployed forecasting models using CNN and Random Forest classifiers on large-scale, unstructured datasets (PE files), achieving 78% accuracy with CNN and 99% accuracy with Random Forest.
- Explore the Deployment video on AWS
Resume-analytics
- Developed scalable AI algorithms and models, leading to a 40% improvement in model deployment time and enhancing overall business performance.
- Spearheaded the development of an AI-powered resume parsing tool utilizing OpenAI’s GPT-3.5 model in 5 days.
-
Developed and implemented a user-friendly web interface with Gradio to facilitate seamless resume parsing. Utilized advanced construction methods to optimize code generation and content creation, ensuring alignment with project objectives and providing actionable recommendations for improvement.
- Explore the Hugging Face Space
Awards & Scholarship
- 2023-2024 TCoE Endowed Graduate Fellowship, recognizing excellence in technology and engineering research.
Publications
- Comparative Study of Generative Models for Early Detection of Failures in Medical Devices, Conference ICMHI 2024.
Volunteering & Leadership
- Data science club University of New Haven
About
Experienced Machine Learning (ML) engineer with over 5 years of expertise in data analysis, optimization, and research in Generative AI. Continuously learning to stay abreast of the latest trends in data science. Notable projects include developing generative models for fault detection in medical devices, achieving 97% accuracy, and enhancing a multilingual transformer-based Text-to-Speech (TTS) system for low-resource languages, which achieved a mean opinion score of 4.2 out of 5 in 6 months through innovative approaches. Led brainstorming sessions to identify new opportunities in testing automation, reducing testing time by 40%. Implemented and maintained a speech conversation chatbot, improving user experience by 40% through effective MLOps deployment and management.
Contact Information
- Mobile: +1-860-944-5353
- Email: bahareh.arghavani@gmail.com
- LinkedIn: Bahareh Arghavani Nobar
- Hugging Face Space: Visit my Hugging Face Space
- Github: https://github.com/barghavanii
Feel free to reach out for collaborations or inquiries!